
Why user needs are key for data-driven decisions
This post builds on ideas presented in the live webinar ‘Designing for impact: How data and design can transform philanthropic decision-making’. See the recording of the webinar below.
Imagine making critical decisions based on incomplete or misleading information – unfortunately, this is the reality for many organisations relying solely on raw data. But what if the key to more informed, impactful decisions isn’t just in the data itself, but in understanding the people who create it?
We've learned that effective data-driven decisions stem from understanding the motivations, challenges, and environments of those generating the data – aka the “data creators”. Relying solely on existing data without considering these factors risks missing critical insights, leading to incomplete or even misleading conclusions.
In this blog post, we’ll delve into why user needs are paramount in data-driven processes and how engaging with data creators throughout the design process can dramatically enhance the quality and impact of decision-making.
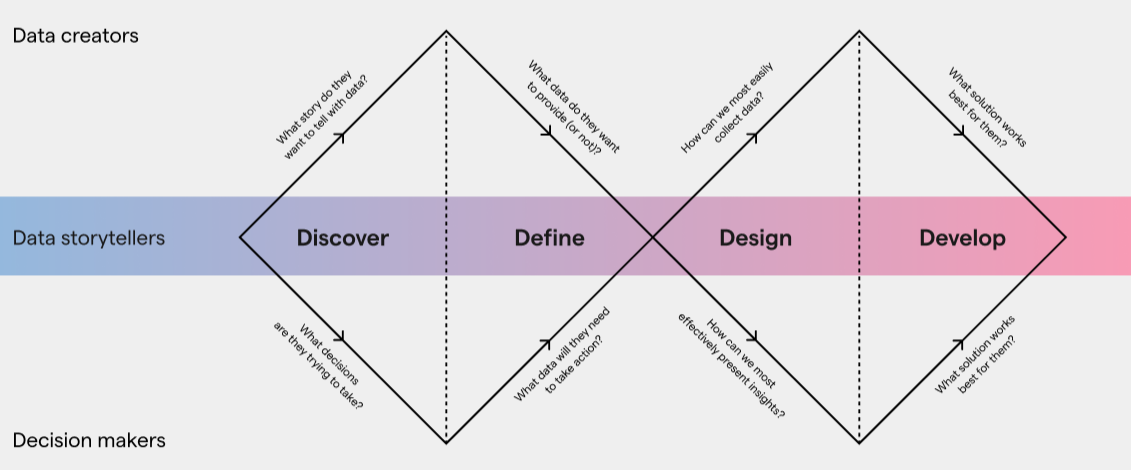
We developed our approach to designing for data-driven decision-making with our partner Applied Works, and we call it “the double diamond of data storytelling”. If you’re a designer or participate in design work, you may recognise the double diamond as a Design Council divergent-convergent design methodology. It expresses how researchers explore a broad set of different ideas before settling on a cohesive approach, and then explore different design ideas to achieve the outcome.
Our approach also explicitly recognises the data creators as an important part of the design process. Using real examples, I’ll explain why we use this approach and why data creators are so crucial.
The data you have may not be the data you need
“What gets measured gets managed. Even when it’s pointless to measure and manage it, and even if it harms the purpose of the organisation to do so.”
Most people only use half of a single diamond when they approach a data analysis problem! They think about what data they’ve got and work out how to present it to decision makers to deliver insight. That’s the bottom half of the second diamond, and by itself it can’t produce the best data-driven decision-making.
The problem is that you might not start with the right data to get the insight you want. And even if you can learn something, can you learn enough to take the right action?
We can illustrate this through work we did with the Ministry of Justice on improving their Community Accommodation Scheme (CAS) with our partners Oxford Insights. MOJ runs CAS to provide alleged offenders with temporary accommodation to be bailed to, keeping them out of a valuable and high-pressure prison bed. The scheme requires court or remand prison staff to write an application on behalf of the alleged offender, which may not be successful if they are deemed too high risk.
Building a model of “enough” data
MOJ wanted to increase the number of successful applications to further reduce pressure on prison beds. Initially, we explored the existing data which showed why applications were failing and hypothesised improvements that could make more of them successful. However, when we analysed the service holistically, we realised that the available data didn’t include anything about applications that weren’t being made – the design of the service made that failure case completely invisible! Getting more applications made might be a much easier or productive avenue to increase successful applications – or it could be less useful.

We realised that new data collection was needed, but what data do we need? If MOJ did find that there are a lot of unmade applications, their next question would be why. So, we needed to collect enough information to answer that too: we proposed to also collect data on the reason why applications aren't made – and we had a set of possible reasons from doing earlier qualitative research with the data creators, aka the court and prison officials.


But once we’d learned that the reason is, say, lack of suitable beds, what then? Well, we can propose an intervention, which is to get more beds. But what data would we need to do that? Given that beds are gender-segregated, and sometimes need to accommodate people with mobility needs, and may need to be in certain locations, we'd need to know all of these things to effectively solve the problem. Without that data we can't take action, or risk taking random action that is wrong – so we need to collect this data too.
Data collection that meets user needs
We now had a management information model that would allow MOJ to understand the biggest contributors to application numbers and contained enough data to let them take action to solve any of the problems that might be uncovered. We needed a method to collect the new data, at a new touchpoint in the journey – after the data creator had made a decision to not make an application.
As per our double diamond, we developed several different prototypes to test with our data creators, which included the GOV.UK-style web form above for recording individual cases and a spreadsheet upload (which the Data Upload Design Kit can help with) to collect a week’s worth of cases at once. As we were part of a service team, we naturally developed these prototypes to be part of the application service itself.
In testing, we realised that because our service was set up to “make applications”, data creators wouldn't be naturally visiting it when they weren't going to make an application. Uptake would be low and our new data collection would be just another process fighting for their attention. So we realised that the best place to collect data was somewhere else entirely – in the case management system that our data creators were already using to record contact with alleged offenders. This required us to make an intervention in a completely different way technically than we’d initially imagined – and all because we’d engaged closely with data creators throughout.
Good outcomes require understanding data creators
Our general principle is that to get a good outcome, you need to do research with your data creators and analyse your data creation process:
You need to hypothesise about what your root causes can be, and collect enough data to differentiate between them
Then you need to hypothesise about what action you might take, and collect enough data to implement them
And you have to consider where and how you'll collect this data, because in context it might make more sense outside of your service
It's all part of solving the whole problem.
Understanding the incentive of your data creators is key
In the previous example, we discovered through testing that the incentives and motivations of our data creators would have a big impact on data completeness and quality. If we'd picked the wrong place or wrong method, we wouldn't have got good results.
This is a more general principle. If we don't consider the needs of our data creator users, we risk their lack of incentive resulting in not collecting all the data we need or not having people execute our process properly.
Mandating a process doesn’t make incentives go away
You might be thinking, “I can just mandate that people follow my process,” but it’s worth remembering that mandated processes will still fail if they are not aligned enough with user needs, and often in more difficult to detect ways. Mandation risks turning something into a ‘tick box exercise’ that is done as quickly as possible or not at all if it can be avoided with impunity – so you would also need to think about how your mandation will be monitored and enforced.
Relying on a process being mandated leads to lower data quality and riskier decisions. Instead, consider how to make it something that users want to do, or at least something that is easy for them to do. We took part in a “Crazy 8s” session run by TPXImpact and together we came up with ideas that can create incentive where there is currently none – like gamification or competition between teams.
User incentives affect technology choices
We can explore the impact of incentives through work we did for the Department of Health and Social Care (DHSC) on their medical devices Product Information Management (PIM) system with our partners Marvell Consulting. DHSC wanted to unlock more strategic policy-making by collecting data about medical devices from the 10,000 suppliers or manufacturers of medical devices in the UK.

We analysed the existing data flows between decision-makers (DHSC) and data creators (manufacturers) and learned a lot about what would and would not work in creation of a new PIM system. Firstly, the data flows demonstrated much duplication: some data was being recorded in multiple places already, and we discovered through research with data creators their significantly reduced motivation to start adding data to a whole new place.
Secondly, we found that one data flow was much more significant than the rest, and that was the direct link between data creators and care practitioners in the NHS. We found that data creators were strongly incentivised to reply when they knew someone needed help to use their product. They were less interested in providing this data up front into a data store without a clear user for it, especially as none of the places they were required to send data provided any sort of feedback about how useful it was. They viewed all of their existing data sharing as a compliance gateway and as a result the data was lower quality and less current than the data provided directly to the NHS.
Finally, because we knew that the choice of technology that we impose on our data creators would have big implications for how much engagement we get, we trialled lots of different data sharing mechanisms. Our research uncovered a wide range of technical capabilities:
The smallest data creators could only handle sharing data via a web form in the browser
Larger data creators were not necessarily more technical but had many more products, making a browser-based flow impractical – so the only answer for them was sharing data via spreadsheet
The most capable data creators (which weren’t necessarily the biggest) pushed hard for APIs, and didn’t want to consider any lower-tech options
Our eventual realisation was that there wasn't one mechanism appropriate for everyone – we would only get the best results by providing several of them for data creators at different levels of technical capability and scale.
Good outcomes require understanding data creators
So to get a good outcome, again the general principle is that you need to understand your data creators’ needs:
Understand their technical capability and data volume: what tools can they use? Which are beyond them or too limited for them? How can you make the tools simple to use? (Pro tip: use the Data Upload Design Kit to make spreadsheet upload simple!)
Understand their incentives: how can you give them feedback that their data is valuable? How can you avoid duplicating work for them?
In fact, we’ve written about the needs and incentives of data creators before – it’s all considered as part of the Four Pillars of data architecture!
User needs are key to data-driven decision-making
In a nutshell, making decisions based on data isn’t just about the data itself. It’s also about understanding what the people who create the data need and want. Our “double diamond of data storytelling” approach shows that we should think about the whole process of creating, collecting, and using data – and not just how to analyse it.
By talking to the people who create the data, we can guess why there are gaps in the data and keep testing and getting feedback. This helps us get more accurate and useful insights. Ultimately, by fostering a culture that values user incentives and understands technical capabilities we can make sure that data collection is both meaningful and sustainable, and it will help us make better decisions in all sorts of situations.
If you need help to apply user-centred design principles to your data-driven processes, get in touch with me and the team at Register Dynamics.
Author
